Informally, random variables are real-valued functions on probability spaces. Such functions induce probability measures on , which encompass all of the familiar probability distributions. These distributions are, essentially, probability measures on the set of real numbers; to formalize this, we need to be able to articulate probability spaces with as the sample space.
The Borel sets comprise the smallest -algebra containing all intervals contained in . We will denote this collection by ; while it is possible to generate constructively from the open intervals as a closure under complements, countable unions, and countable intersections, doing so rigorously is beyond the scope of this class. Importantly, however, contains all intervals and all sets that can be formed from intervals; these will comprise our “events” of interest going forward.
Concepts
Let be a probability space. A random variable is a function such that for every , .
If , and , define: Then is a random variable since for any : So .
Not all functions are random variables. For example, take and the trivial -algebra , and consider ; then .
The condition that preimages of Borel sets be events ensures that we can associate probabilities to statements such as or, more generally . Specifically, we can assign such statements probabilities according to the outcomes in the underlying probability space that map to under . Thus, random variables induce probability measures on .
More precisely, if is a probability space and is a random variable, then the induced probability measure (on ) is defined for any Borel set as:
The induced measure is known more commonly as a probability distribution or simply as a distribution: it describes how probabilities are distributed across the set of real numbers.
You’ve already seen some simple random variables. For example, on the probability space representing two dice rolls with all outcomes equally likely, that is, with and , the function is a random variable, because . Moreover, the probability distribution associated with is:
As determined in a previous homework problem, only for , and the associated probabilities are:
Cumulative distribution functions
We must remember that the concept of a distribution arises relative to some underlying probability space. However, it is not necessary to work with the underlying measure — distributions, luckily, can be characterized using any of several real-valued functions. Arguably, the most fundamental of these is the cumulative distribution function (CDF).
Given any random variable , define the cumulative distribution function (CDF) of to be the function:
Consider the dice roll example above with the random variable . Fill in the table below, and then draw the CDF.
If the random variable is evident from context, the subscript can be omitted and one can write instead of .
Theorem. is the CDF of a random variable if and only if it satisfies the following four properties:
- is monotone nondecreasing:
- is right-continuous:
We will prove the ‘necessity’ part: that if a random variable has CDF , then it satisfies (i)-(iv) above. For sufficiency, one must construct a probability space and random variable such that has CDF ; we will skip this argument, as it is beyond the scope of this class.
For (i), observe that is a nonincreasing sequence of sets for and . Then:
For (ii), observe that is a nondecreasing sequence of sets for and . Then: For (iii), note that if then , so by monotonicity of probability .
For (iv), let be any decreasing sequence with . For instance, . Then the sequence of events is nonincreasing, and , so:
The portion of this theorem we didn’t prove is perhaps the more consequential part of the result, as it establishes that if is any function satisfying properties (i)–(iv) then there exists a probability space and random variable such that . This means that we can omit reference to the underlying probability space since some such space exists for any CDF. Thus, we will write probabilities simply as, e.g., in place of or . Consistent with this change in notation, we will speak directly about probability distributions as distributions “of” (rather than “induced by”) random variables.
It’s important to remember that distributions and random variables are distinct concepts: distributions are probability measures ( above) and random variables are real-valued functions. Many random variables might have the same distribution, yet be distinct. Since CDFs are one class of functions that uniquely identify distributions, if two random variables have the same CDF (that is if ) then they have the same distribution and we write
Two convenient properties of CDFs are:
- If is a random variable with CDF , then
- If is a random variable with CDF , then
The proofs will be left as exercises. This section closes with a technical result that characterizes the probabilities of individual points .
Lemma. Let be a random variable with CDF . Then , where denotes the left-hand limit .
Define ; then and is a nonincreasing sequence with . Then:
Notice the implication that if is continuous everywhere, then for every .
Discrete random variables
If a CDF takes on countably many values, then the corresponding random variable is said to be discrete. For discrete random variables, is called the probability mass function (PMF) and the probability of any event is given by the summation:
It can be shown that discrete random variables take countably many values — i.e., for countably many . We call the set of points where the probability mass function is positive — — the support set (or simply the support) of (or its distribution).
Theorem. A function is the PMF of a discrete random variable if and only if:
If is a PMF of a discrete random variable , then by definition the PMF is . Since by monotonicity of , for every . Since and is monotonic, for every ; by construction . So .
For the converse implication, if is a function satisfying (i)–(ii), then for only countably many values. To see this, consider for with ; by construction we must have for every since is nonnegative per (i) and . Now on so ; but then if is infinite the sum on the right diverges, and thus so does the sum over all contrary to (ii). So (ii) entails that for every , and thus the union is a countable set.
Let denote the set . Let denote the elements of and denote the corresponding values of , that is, . By hypothesis we have that (condition (i)) and (condition (ii)). Let for . Then is a probability measure on — it suffices to check that satisfies the probability axioms.
- Axiom 1: since by hypothesis .
- Axiom 2: .
- Axiom 3: let be disjoint and define . Note that and for . Then:
So is a probability space. Now let be the identity map . is a random variable, since for every , and its CDF is given by . This is a step function with countably many values, so is a discrete random variable. Finally, it is easy to check that:
So has PMF as required.
This result shows that PMFs uniquely determine discrete distributions. It also establishes that the support set is countable, so the unique values can be enumerated as . We can recover the CDF from the PMF as .
Continuous random variables
If a CDF is absolutely continuous everywhere then the corresponding random variable is said to be continuous. In this case, for every and so we define instead the probability density function (PDF) to be the function such that
By the fundamental theorem of calculus, one has that . The probability of any event is given by the integral:
For continuous random variables, the support set is defined as the set of points with positive density, that is, .
Similar to the theorem above for discrete distributions, it can be shown that a function is the PDF of a continuous random variable if and only if:
The proof of this result is omitted.
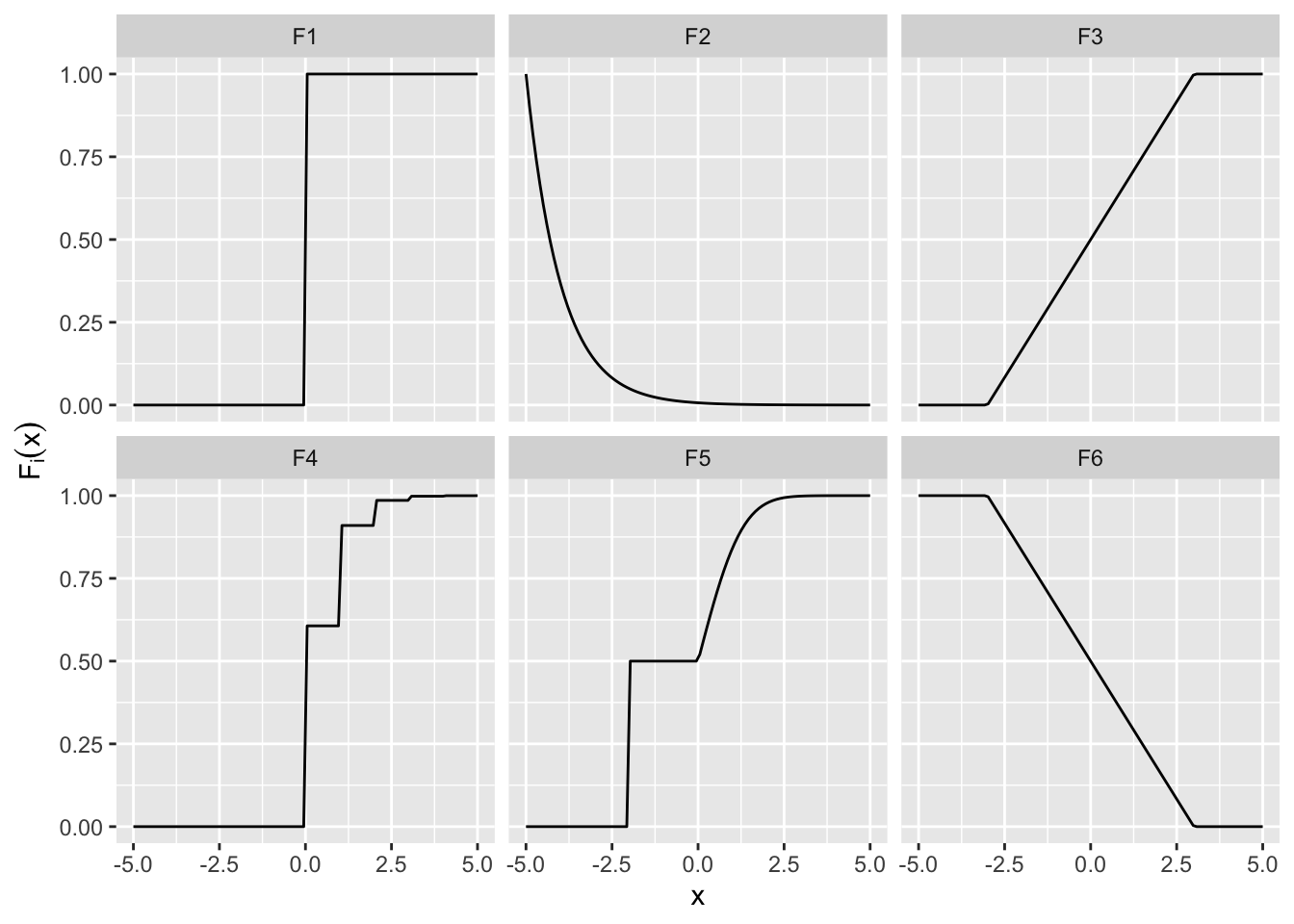
For each of the functions below, determine whether it is a CDF. Then, for the CDFs, identify whether a random variable with this distribution is discrete or continuous, and find or guesstimate the PMF/PDF if it exists. You can ignore the behavior at the endpoints, but to check your understanding, identify for each jump which value the function must take at the endpoint for it to be a valid CDF.
These results establish that all distributions (again, recall that technically distributions are probability measures on induced by random variables) can be characterized by CDFs or PDF/PMFs. If a random variable has the distribution given by the CDF or the PDF/PMF , we write
respectively.